Towards a Universal Representation of Language
Transformer-Based Architectures for Information-Dense Linguistic Kernels
I found myself in the perplexing position, recently, of authoring a fresh research proposal for my application to a doctoral program in engineering, despite (technically) still being enrolled on a course for a PhD in physics. Central to my proposal was a hybrid machine-learning architecture seeking to mesh natural language processing and weather forecasting using a combination of transformer units and generative adversarial networks. It was, approximately, four-and-a-half minutes after the submission deadline that I realized everything in my proposal was dead wrong.
The Dead Poet Metric
Or at least half-wrong. The self-assessment of my research proposal which I unveiled rather melodramatically at the conclusion to the preceding paragraph brings to mind the famous scene in Dead Poets Society, where the ambiguously and not-at-all ham-handedly-named Keating (Robin Williams) mocks an antediluvian literary critic's prescription for the appraisal of canonical literature, wherein one is asked to assign a work some coordinate in 2-dimensional space before subsequently computing its value, via the formula . I invoke this scene here because my aforementioned research proposal was "dead wrong" only in the sense that it underperformed severely when operating by the metric (with its value ostensibly left to the deliberation of a thesis committee in half a decade's time). Simply put, buried in my proposal was the essence of a far better idea, though perhaps not one as worthy as the generous score ascribed to Shakespeare on Keating's blackboard, seconds before this framework is quickly abandoned for late-20th century cinematic hijinks culminating in a moral lesson about how problematic single-sex education can be (or how Robert Sean Leonard has good cheekbones, or something).
Baked into my proposed model was (is) an intermediate "code" layer produced by an encoder-only transformer (later I'll call this, rather pompously, a "linguistic kernel"). This in-and-of-itself is relatively mundane (though it is worth noting that the most popular transformer-based LLMs, namely ChatGPT, Claude, Gemini, Grok et al. actually employ a decoder-only transformer), and understandably will stoke little excitement in the ML-literate reader (I have generously assumed that the rest of you surrendered after my first mention of Dead Poets to return to lives more oriented to human interaction than gradient descent strategies). Then I started reading (re-re-re-reading) Jurafsky and Martin's excellent textbook on natural language processing, and finally understood what had been scratching at the back of my mind ever since I submitted my proposal.
Language is Absurd
Language is, for lack of a better word, utterly bizarre. Young infants achieve fluency in their native language with seamless ease, somehow emerging from a silent, uncomprehending state into a level of command which many adults find difficult to achieve in a second language. Additionally, it's still an open question exactly how we process language (as suggested by various studies of, among other things, priming, bias, mental illness, verbal abuse, sexual attraction, politics, fascism, strokes, evolutionary ethology, literature, religion, tobacco advertising, suicide reporting in the press, misinformation, child-rearing, and large language models). Furthermore, there's no convincing a priori justification (to my mind) stating all languages are or should be processed by humans equally; indeed, it could be argued that entrenched practices bequeathed by one language (systems of numbering, presence/absence of noun case and gender, word order) are equally as obstructive as they are constructive in the pursuit of learning other languages. You'll often find linguists proficient (either verbally fluent or literate) in a diverse array of languages, but in my experience this usually stems from their ability to construct a meta-framework, or a "language of languages" rulebook, that allows them to assess variations between languages by some common understanding of how they work.
Jurafsky and Martin eureka'd me into my realization by considering the manifest differences between languages which directly impact tokenisation, in addition to other stages of natural language processing. Take, for example, Latin versus English. I had the mixed experience of having studied it for about five years as a kid, from the age of twelve until I was almost seventeen. Latin's influence on English is immense and readily-apparent from the outset of learning the language (senex to "senile", mendax to "mendacious", via to, well, "via", and countless other examples I've refrained from highlighting). Regardless, they are, in many ways, linguistic antipodes. Word order in English is relatively rigid- subject precedes object (known in shorthand by the acronym SVO). That's why "the dog ate the boy" has precisely (and, in a language mostly lacking case, necessarily) the opposite meaning to "the boy ate the dog", despite the fact that the two phrases are identical in terms of the words they contain. We can see that positional encoding is therefore of paramount importance to a transformer-based model constructed for processing the English language.
Latin, especially in contemporary literature, eschews this almost entirely- there are some common threads (such as verbs concluding the sentence; this is designated SOV structure), but this is utterly optional. Verbs often succeed or precede their subject at will, as required by emphasis or context. Ambiguity as to which of the dog or boy is eating the other is resolved by explicit inclusion of case in the suffices of nouns. Punctuation is almost entirely absent, and indeed would be utterly useless if present owing to the fluidity of word order convention. Furthermore, consider the baroque and complex conjugation of Latin verbs. There are several moods (e.g. indicative, infinitive, subjunctive), six cases (nominative [subject], vocative, accusative [object], genitive, dative, ablative), and a complex set of rules for subordinate clause construction (purpose clauses, indirect statements, indirect questions), all of which are utterly alien to a native English speaker. Verbs can be used as adjectives, as in English, in the form of participles, but the extensive and convoluted declension of participles matches that of ordinary nouns. There is no shortage of strange corollaries to this practice, including the existence of the strange but somewhat poetic perfect passive participle "having been fallen". Producing tokens in the Latin Large Language Model ("LLLM") would produce a whole host of further difficulties. This includes the need to perform lemmatisation on a large number of words which are actually diverse forms of the same verb before encoding a relationship between all of them, either in some vector embedding space or otherwise. Additionally, employing positional encoding would be counterproductive in such an "LLLM" where word order often changes to reflect context or authorial intention.
In English, we've largely eliminated these issues- consider the relatively simple conjugation for the vast majority of English verbs (I walk/you walk/she walks/we walk/you (pl.) walk/they walk), or the fact that cases are replaced by the presence of other structures ("of" or the possessive apostrophe for the genitive case) or, as shown before, by word order (whoever is doing the eating comes first in the sentence). Word endings almost never change regardless of case (with exceptions for pronouns: who/whom, he/him, etc.). It's objectively easier (not a legally-binding assertion) learn English than Latin, and its comparative simplicity over Latin is potentially a factor in its status as an extant, rather than extinct (c.f. Latin), language.
A Token of (In)gratitude
Hopefully this digression into my classical education helps to illustrate my point. Don't even get me started on Ancient Greek, which shares many of Latin's obscure complexities while also presenting the compounding difficulty of having another alphabet.
Jurafsky and Martin's book used the example of the Mandarin language to belabour this point. Before, I used Latin as my exemplar, partly because of my proficiency in it, partly due to my utter lack of experience with Mandarin in any form, and partly to avoid plagiarising their book. In Jurafsky and Martin's case, they point out that reading Mandarin through the English lens is incredibly problematic, owing to the lack of spacings between words, and the fact that multiple competing schemes of "segmentation" exist in parsing Mandarin. Here, by "segmentation", we refer to methods of grouping adjacent characters together. Here is the example they use:
姚明进入总决赛 -> Translation: "Yao Ming reaches the finals"
Here is a proposed way of "segmenting" Chinese into three "words" (though note we mean "words" loosely in this context):
姚明
Ant this is a method of splitting into five:
姚
This highlights the challenge of tokenising languages with written representations similar to Mandarin (e.g. Japanese or Thai, also named by Jurafsky and Martin). We can see here that a simple byte pair encoding scheme may succeed in understanding cases in which certain characters can either be "segmented" into one "word" or parsed separately, but they'd struggle to develop a baseline vocabulary of words as they would be able to do in English, or in scripts with explicit spacing. One potential scheme could involve tokenising the same sentence twice, in line with both, rather than just one, of the above segmentation schemes. However, this requires some sort of human-designed judgement call from us, and ideally, in order to streamline the LLM-creation process, we'd simply pass our predesigned model one large corpus (or series of corpuses) in the exact format it appears after being produced by a human.
There is No Universal Representation of Human Language, but There is a Universal Human
We arrive at the point- there is no universal representation of human language.
Or is there?
Humans are much alike. Our best predictors of personal preferences, wealth, employment, and beliefs are often sociological and economic rather than biological. Yet, despite significant overlap, a series of social and cultural mutations ("copying errors") produced a diversified gallimaufry of linguistic traditions that somehow work for all of us. Perhaps there exists an "easiest language", but one would be hard-pressed to argue that this makes it the "best" or the most "worthy". Perhaps if we all started working in base 60 and learnt the language of Ancient Babylonians, we'd be better at arithmetic. Maybe Romansh is the language most conducive to reciprocal human attachment and romantic bonding. But these questions have unknowable answers. We do know is that billions of people across the globe all speak languages. We know that the overlap is dwarfed by difference- no system has (yet) attained a global majority when it comes to first languages. People who grow up speaking the same language learn to do so in different accents across differing dialects with differing slangs or vernaculars. Yet, somehow, this system persists without some "universal language" percolating up from our collective subconscious, much as Frederick II might have expected in the famous fable of him raising children in isolation from human speech.
It is precisely this problem onto which I think we should turn the full battery of the natural language processing apparatus- can we create a universal, cognitive representation of human language using machine learning?
In this project, we would be tasked with the following: (a) deduce some characteristic or shared set of characteristics common to all spoken human language, (b) create a universal large language model, "ULLM", which employs the same neural network as well as the same tokenization scheme for all languages, and © relates this credibly to underlying trends in human neurology and psychology, creating a verifiable theory of how languages once developed (and continue to develop) in human society. We can then look at doing (d) answering the "NewSpeak" question- are certain thoughts easier or harder (or perhaps impossible) to "have" in different languages? In our reduced-dimensional representation, do certain languages score higher and lower in some syntactic/"cognitive load" categorizations?
In short, we seek to develop a universal representation of language.
Dense Linguistic Kernels
We explored the difficulties of tackling multiple languages with modern methods of natural language processing. Then, I presented the theory that it is possible, theoretically, to deduce a universal representation of language, and that we can measure the accuracy and viability of this representation by implementing it as a language model and seeing how well it performs across multiple languages without changing its schema of tokenization or the structure of its neural network. Simply the existence of such a model that produces any nonzero (or better-than-random) accuracy across multiple languages would implicitly prove the existence of at least a heuristic, quasi-universal model for language or potentially a family of languages. A subset of this task that appears immediately more realistic would be the construction of such a model for some group of languages, such as the Romance languages, whose common characteristics are a well-documented field of academic research, and for whom some "universal representation" seems readily achievable, at least in part.
Reconstruction from reduced representation is an active field of machine learning research. More generously, it is a tried-and-tested branch of the discipline, the byproducts of which have included powerful structures such as autoencoders, capable of reproducing data of some dimension from an intermediate representation of dimension where .
We imagine leveraging the power of transformers, whose ability to powerfully encode context and shared meaning across a series of input tokens has resulted in contemporary LLMs. Despite their expressivity and success, transformers account for only a small fraction of LLM parameters (most is accounted for by multi-layer perceptrons). This leveraging would involve using a transformer to "encode" corpuses of text, or indeed entire languages, into some dense, knowledge- and information-rich representation. These are our kernels- some learned/discovered, indivisible and granular representation that captures a limited set of common features shared across all languages.
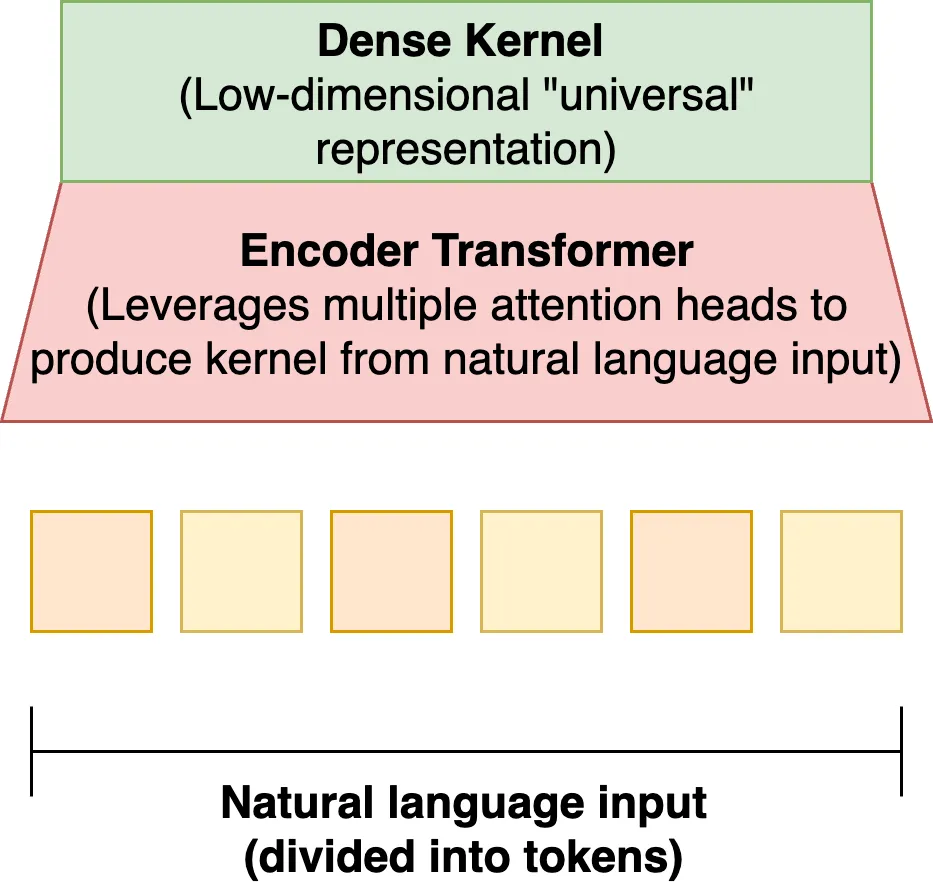
In order to do this, we may have to look beyond language as, exclusively, batches of text of slices. We need to look at smart ways of encoding syntactic rules, case ordering, written complexity, and how different languages use different mechanisms to convey the same meaning (French does not distinguish between preterite and perfect, but the language can describe everything English can). We need to find smart ways of engineering input to a neural network that encodes more than just words and their positions, and on top of all of this, we need to make each input look something like a vector.
There's no obvious or easy way to do this. That doesn't make it impossible- position encodings can be concatenated onto token vectors in current LLMs, and I see no reason why, for example, word length, relative position to the verb/subject/object, gender, root, or similarity across verb/noun forms for the same root when the word appears either in a different case (if a noun) or different tense (if a verb). We may find that Word Order 1 with Case and Gender Structure 1 in Language 1 somehow paradoxically forms a demonstrably identical representation as Word Order 2 with Case and Gender Structure 2 in Language 2 (you can get 6 by adding 3 to 0 twice or dividing 12 by 2 once).
Further, we could look at training a model not on words and text itself, but on symbolic representations of how the sentences and works of the languages themselves are constructed, producing input data to a "syntactic processor" network that accounts for word order, frequency of contraction/elision, case declination, punctuation, and any other features of syntax we want to investigate- this would be performed instead of (or in addition to) conventional natural language processing from text. There is of course the possibility of combining these two input data types- both syntactic and textual literal- into one unified input. One could imagine the following embedded representation of some work or set of works in some language.
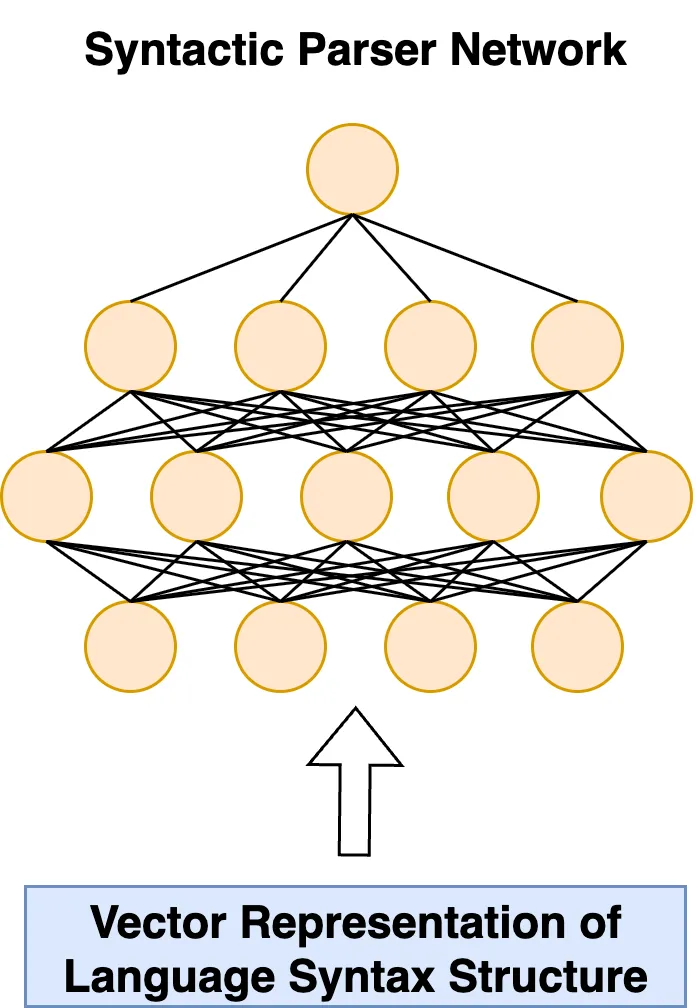
and the rest is a small matter of several years' worth (minimum) of data accumulation, text processing, and intensive engineering, with consistent access to a state-of-the-art data center.
Transformers, Not Humans
It's already obvious that the transformer, and machine learning as a field, falls far short of human performance. This statement may seem (or, in fact, simply be) controversial or naive- but it's clearly true. Transformers have a finite context window, and eventually lose track of the narrative thread. Conversely, in a healthy human, there is no well-defined limit on longevity or depth of human memory. People routinely remember events, novels, days, films or experiences long past, and although these memories are seldom accurate, their mere existence as some "best-guess" approximation at reality speak to a power that LLMs cannot yet rival. Furthermore, LLMs are, candidly, reaching a plateau that humans have not (just observe the diminishing returns as OpenAI migrates from GPT-4 to GPT-5). The requirement that modern LLMs with trillions (soon, undoubtedly, hundreds of trillions) of parameters be trained at a cost of millions on state-of-the-art GPUs for timescales on the order of days should be the loudest klaxon that something crucial is missing from the picture. Humans, as far as we can tell, don't train on backpropagation, and we don't need a data center to learn how to read. Human teenagers outperform self-driving cars after significantly fewer hours behind the wheel. And they're usually not even old enough to drink.
The transformer is not a human. More precisely, it cannot and does not mimic human cognition. Nor are modern LLMs multimodal, at least not in the sense in which we can apply that word to human beings, who are capable of sleep, painting, intuition, mathematics, and language, all at a fraction of the cost. This is not to disqualify machine learning as a field. It's simply about building a better model.
When he sought in the 1920s to formulate a relativistic theory of quantum mechanics, Paul Dirac wrote down his now-famous equation:
and though he drew on Schrödinger and Einstein, his insight was entirely unique, coming about not by sticking new spokes on the wheel, but by building a better wheel. No one knew what the Dirac equation would look like until it was written down. Neither will we know what the successor to the transformer will look like until we build it. Though if I had to take a guess, I conceive of something less linear. The human mind does not sequentially access memory. Nor, I imagine, does it sequentially access most information that it's given. Humans glance, glance again, read, re-read, read out of order, and don't tokenize by byte pair encoding. What we need is something spherical, something that curls back on itself, where context is encoded three-dimensionally and not two-dimensionally, something that draws on experience and heuristics the way that we do, takes multiple passes while remembering different things and logs the intermediate results. Maybe this third dimension is output from previous passes of the same sentence- maybe it's a memory cache or a symbiotic "memory" network which constantly supplies context or modification or substitution to input phrases and text before it even enters the main model as we try to mimic the science of what we still do not know. What does memory look like in a human mind? In LLMs it looks like the weights between fully-connected layers. But the human brain doesn't use activation functions, or at least none that look so simple. That's the immense task for the next generation of natural language processing. But so was building an LLM in the first place. And so was inventing the transformer (and so was inventing the computer).
But who could possibly know the answer to any of this. The best thing about the future is you can never look there.